前言
Ceph是一个多版本存储系统,它把每一个待管理的数据流(例如一个文件)切分为一到多个固定大小
的对象数据,并以其为原子单元完成数据存取。
对象数据的底层存储服务是由多台主机组成的存储集群,该集群也被称为RADOS存储集群,即可靠、自动化、分布式对象存储系统。
相关地址
- 官方地址: https://ceph.com/en/
- 官方文档: https://docs.ceph.com/en/latest/
- GitHub地址: https://github.com/ceph/ceph
- 下载站: https://download.ceph.com/
- 红帽文档: https://docs.redhat.com/zh_hans/documentation/red_hat_ceph_storage
- 本文参考: https://blog.swireb.cn/docs/ceph
Ceph的特点如下: - 功能强大:Ceph能够同时提供对象存储、块存储和文件系统存储三种存储服务的统一存储架构。
- 可扩展性:Ceph得以摒弃了粗汉同的集中式存储元数据寻址方案,通过Crush算法的寻址操作,有相当强大的拓展性。
- 高可用性:Ceph数据副本数量可以由管理员自定义,并可以通过Crush算法指定副本的物理存储位置以分隔故障域,支持数据强一致性的特性也使Ceph具有了高可靠性,可以忍受多种故障场景并自动尝试进行修复。
访问接口 - RADOS
RADOS是Ceph存储系统的核心提供分布式对象存储服务
所有的数据都会被拆固定大小的对象(通常为4MB)并通过RADOS存储在Ceph集群中
RADOS使用CRUSH算法来确定这些对象应该存储在哪些OSD设备上
其他存储接口(RBD、CephFS、RGW)都是构建在RADOS之上的
适用于需要直接操作对象存储的高性能应用 - 对象存储接口
RGW是Ceph提供的对象存储接口
支持S3和Swift协议
用于构建兼容AWS S3和OpenStack Swift的对象存储服务
适用于需要对象存储的应用(如云存储、备份和大数据存储) - 块存储接口
RBD是Ceph提供的块存储接口
将Ceph对象存储抽象为虚拟块设备
适用于需要块存储的应用(如虚拟机、数据库和容器存储) - 文件系统接口
CephFS是Ceph提供的文件系统接口
将Ceph对象存储抽象为POSIX兼容的分布式文件系统
适用于需要分布式文件系统的应用(如NFS、SMB等共享存储)

各类组件
核心组件
一个Ceph存储集群至少需要一个Ceph Monitor、Ceph Manager和Ceph OSD(Object Storage Daemon对象存储守护进程)。此外如果有运行Ceph文件系统的客户端还需要配置Ceph元数据服务器。
关于各个组件的作用,可参考下表
| 组件 | 角色 | 最小数量 | 建议数量 |
|---|---|---|---|
| Monitor (MON) | 维护集群的映射和状态信息 | 1 | 通常建议有至少3个MON节点(高可用集群一般配置为基数方便集群仲裁选举) |
| Manager (MGR) | 提供集群管理和监控功能包括收集性能数据和提供管理界面 | 1 | 至少2个MGR节点(一个主节点和一个备用节点) |
| OSD Daemon (OSD) | 实际存储数据、处理数据复制、恢复、重新平衡等任务(1个OSD通常对应1个存储设备) | 3 | 至少3个OSD节点(在实际部署中通常会有更多的OSD节点以确保数据冗余和分布) |
接口组件
| 组件 | 角色 | 最小数量 | 建议数量 |
|---|---|---|---|
| Metadata Server (ceph-MDS) | 负责管理Ceph文件系统(CephFS)的目录和文件的元数据 | 1 | 2个MDS(一主一备)、3个MDS(二主一备)、根据负载情况部署多个MDS |
| RADOS Gateway daemons (Ceph-RGW) | 提供对象存储接口 | 1 | 至少两个RGW实例(使用简单的Nginx或HAProxy配置来分发流量) |
| RADOS Block Device (ceph-RBD) | 提供块存储接口 | 0 | RBD不需要单独的守护进程 |
监控组件
- Alertmanager 处理Prometheus服务器发送的警报
- Prometheus 是监控和警报工具包(它收集Ceph-exporter提供的数据)
- Grafana 是一个视觉化和警报软件
- Node-exporter 收集和监控单个节点的硬件和操作系统指标
- Ceph-exporter 收集和监控整个Ceph存储集群的状态和性能指标
集群全部节点部署Node-exporter、Ceph-exporter
存储过程
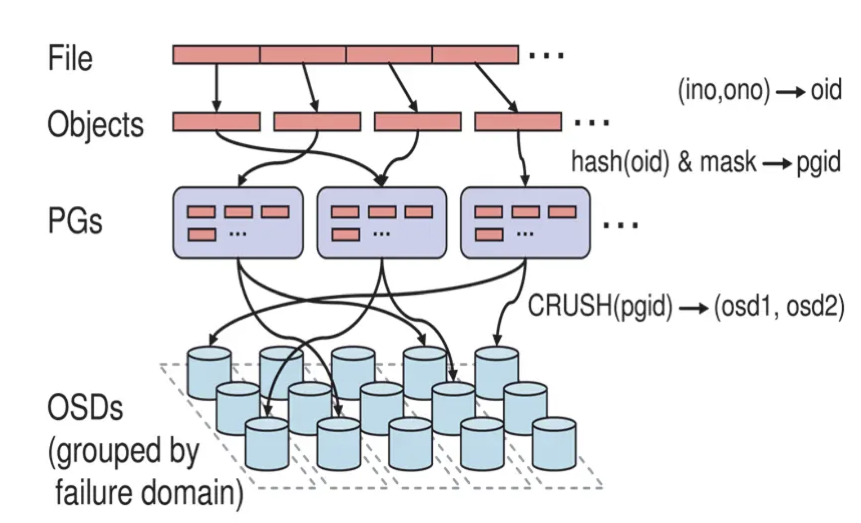
- OSD 是实际存储数据的节点
- 池 (Pools)是逻辑分区,用于组织和管理数据,提供了弹性、放置组、CRUSH规则和配额
- 放置组 (Placement Groups,PG) 是数据分片,帮助实现数据分布和负载均衡
- 存储算法 (CRUSH) 是数据分布算法,决定数据对象存储在哪些OSD上
版本选择
参考地址: https://docs.ceph.com/en/latest/releases/
第一个 Ceph 版本编号是 0.1 ,发布于2008 年 1 月。之后是0.2,0.3.... 多年来,版本号方案一直没变2015 年 4 月 0.94.1 ( Hammer 的第一个修正版)发布后,为了避免 0.99 (以及 0.100 或 1.00?),制定了新策略。x 将从 9 算起,它代表版本名称Infernalis( I 是第九个字母),这样第九个发布周期的第一个开发版就是 9.0.0 ;后续的开发版依次是 9.0.1 、 9.0.2 等等。
x.0.z - 开发版
x.1.z - 候选版
x.2.z - 稳定、修正版本文采用Reef版本 https://docs.ceph.com/en/latest/releases/reef/
部署
环境设置
三台主机组件、配置对应表如下
# 组件规划
node1 #MON、MGR、OSD、Bootstrap、监控堆栈组件
node2 #MON、MGR、OSD
node3 #MON、OSD
# 网络规划
# 每台主机2C2G并且配置双网卡(统一网卡名称)
10.0.0.0/24 #公共网络
172.16.1.0/24 #集群网络
# 系统
Rocky 9.5
# 网络配置
主机名 NAT网络 LAN区段网络
node1 10.0.0.150/24 172.16.1.100/24
node2 10.0.0.151/24 172.16.1.101/24
node3 10.0.0.152/24 172.16.1.102/24
# 硬盘
#每台主机3个磁盘(用于OSD的磁盘不要创建任何分区)
1个50G SSD #系统盘
1个100G SSD #OSD
1个100G SATA #OSD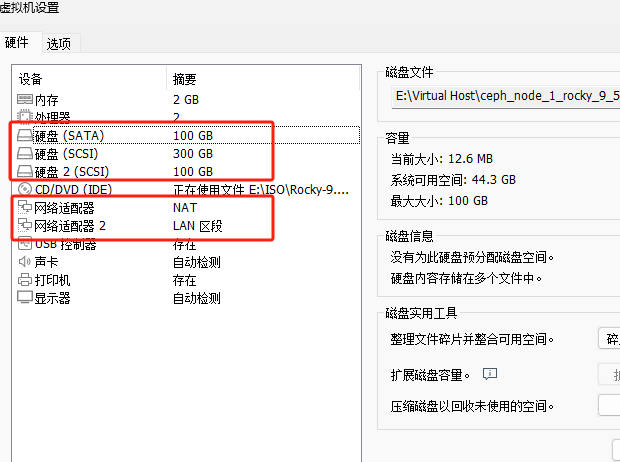
三台Ceph都是这个配置,仨硬盘,我那个300G是克隆出来的是系统盘,100G*2额外加上的,网卡NAT算是外部的,LAN区段是内部通信网络。配置hosts文件,三台主机执行下面命令
cat >> /etc/hosts <<EOF
# Public
10.0.0.150 node1
10.0.0.151 node2
10.0.0.152 node3
# Cluster
172.16.1.100 cluster-node1
172.16.1.101 cluster-node2
172.16.1.102 cluster-node3
EOF基础软件包安装
yum install -y wget lrzsz tree bash-completion vim yum-utils nfs-utils autofs net-tools httpd-tools chrony epel-release时间同步配置为阿里云
#使用路由作为NTP服务端
vim /etc/chrony.conf
server ntp.aliyun.com iburst
#启动时间同步服务
systemctl restart chronyd.service
systemctl enable chronyd.service
#开启时间同步并且配置时区
timedatectl set-timezone Asia/Shanghai
timedatectl set-ntp true关闭selinux和firewalld
systemctl stop firewalld && systemctl disable firewalld
setenforce 0 && sed -i 's/SELINUX=enforcing/SELINUX=disabled/' /etc/selinux/config其他信息
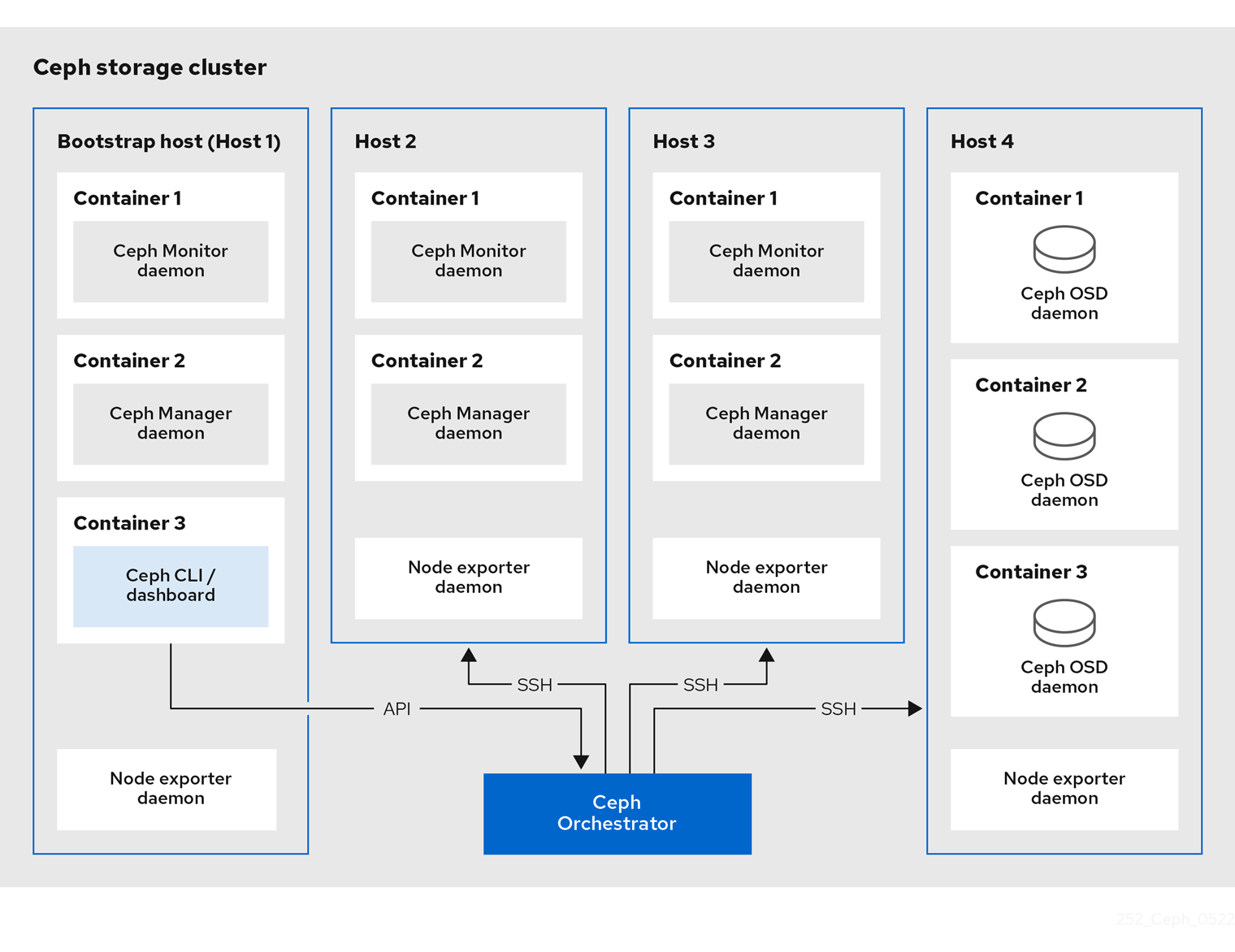
工作原理简述
#Cephadm命令使用ssh与存储集群中的节点通信
无需使用外部工具即可添加、删除或更新Ceph Storage容器
在引导过程中生成ssh密钥对或使用您自己的ssh密钥
#Cephadm Bootstrapping过程
在单一节点上创建一个小型存储集群
包含一个MOG和一个MGR以及任何需要的依赖项(监控堆栈组件)
#初始化集群以后通过横向拓展来完善集群
可以使用Ceph命令行或Ceph仪表板来添加集群节点注意事项
Cephadm仅支持Octopus以后的版本
Cephadm需要容器支持(以Podman或Docker的形式)
Cephadm默认使用Podman作为容器引擎
Cephadm需要Python3(Python3.6或更高版本)
Cephadm需要systemd
Cephadm需要时间同步部署集群
安装docker
# 一键安装docker
bash <(curl -sSL https://linuxmirrors.cn/docker.sh)
# 更换Docker加速源
cat > /etc/docker/daemon.json <<EOF
{
"registry-mirrors": ["https://docker.proxy.boychai.xyz"]
}
EOF
# 重新加载
systemctl daemon-reload && systemctl restart docker安装Cephadmin
参考地址: https://docs.ceph.com/en/latest/cephadm/install/#using-curl-to-install-cephadm
#仅在Bootstrapping节点上安装Cephadm
#直接下载Cephadm二进制文件(推荐这种安装方法)
CEPH_RELEASE=18.2.4
curl --silent --remote-name --location https://download.ceph.com/rpm-${CEPH_RELEASE}/el9/noarch/cephadm
chmod +x cephadm
mv cephadm /usr/sbin
# 增加ceph的yum源
dnf search release-ceph #搜索系统支持的版本
dnf install -y centos-release-ceph-reef #安装reef版本的yum源
#通过官方YUM源安装Cephadm(会默认安装podman不推荐)
dnf install -y cephadm #安装Cephadm
dnf remove -y podman #卸载podman(默认会作为依赖安装)
#安装Ceph命令行工具
cephadm install ceph-common #通过cephadm安装(推荐) 这样安装的版本比较统一
dnf search release-ceph #搜索系统支持的版本
dnf install -y centos-release-ceph-reef #安装指定版本的YUM源
dnf install -y ceph-common #通过dnf安装ceph命令行工具
#可以指定特定的Python来运行Cephadm(极少的情况Cephadm无法调用系统的Python)
python3.9 cephadm version
#确认版本
cephadm version
ceph --version
#检查节点是否满足要求(指定hostname时需要配置SSH免密)
cephadm check-host [--expect-hostname HOSTNAME]
#为Cephadm准备节点(指定hostname时需要配置SSH免密)
cephadm prepare-host [--expect-hostname HOSTNAME]Bootstrap的过程介绍
#Bootstrap的过程简述
在本地主机上为新集群创建MON、MGR守护进程
为Ceph集群生成新的SSH密钥并将其添加到root用户的/root/.ssh/authorized_keys
生成公钥文件/etc/ceph/ceph.pub
生成最小配置文件/etc/ceph/ceph.conf
生成client.admin的特权文件/etc/ceph/ceph.client.admin.keyring
添加_admin标签到引导主机
何具有此标签的主机也将获得/etc/ceph/ceph.conf的副本和/etc/ceph/ceph.client.admin.keyring的副本
#当引导集群时会自动生成此SSH密钥且不需要额外的配置
#Bootstrap语法
cephadm --docker bootstrap --mon-ip <ip-addr> --ssh-private-key <private-key-filepath> --ssh-public-key <public-key-filepath>下面开始初始化node1的环境
创建一个新的 Ceph 集群,并设置第一个 Monitor 节点。这个 Monitor 节点将成为集群的入口和管理节点。
cephadm bootstrap --mon-ip 10.0.0.150 --cluster-network 172.16.1.0/24如果镜像下载比较慢可以尝试使用同步站提前下载
- https://docker.aityp.com/
装好之后的输出信息如下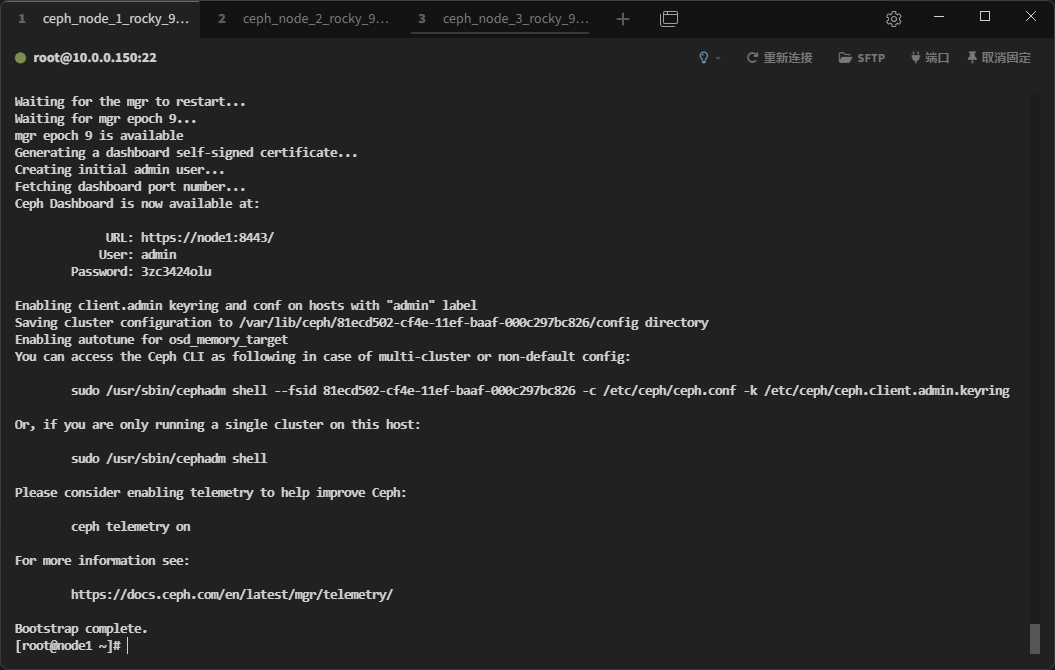
装好之后他还会启动多个容器
具体的作用可以根据容器名字去本文组件部分查看。最新版它不仅仅会把基础的核心组件跑在上面,还会部署监控组件和web面板。在目录/etc/ceph可以看到一些文件,它们的作用如下 - ceph.client.admin.keyring - 管理员密钥文
- ceph.conf - Ceph 配置文件
- ceph.pub - 公钥文件
- rbdmap - RBD 映射配置文件
此时再去执行ceph status就可以看到集群信息、服务信息、数据信息的基础信息了,输出内容如下
[root@node1 ~]# ceph status
cluster:
id: 81ecd502-cf4e-11ef-baaf-000c297bc826
health: HEALTH_WARN
OSD count 0 < osd_pool_default_size 3
services:
mon: 1 daemons, quorum node1 (age 8m)
mgr: node1.tsjrnc(active, since 6m)
osd: 0 osds: 0 up, 0 in
data:
pools: 0 pools, 0 pgs
objects: 0 objects, 0 B
usage: 0 B used, 0 B / 0 B avail
pgs:
progress:
Updating grafana deployment (+1 -> 1) (0s)
[............................] 然后相关的其他面板
#相关仪表盘地址
https://node1:8443 #Dashboard
https://node1:3000 #Grafana
http://node1:9095 #Prometheus现在再去访问他的Dashboard,账号密码都在他的输出信息中,登陆后内容如下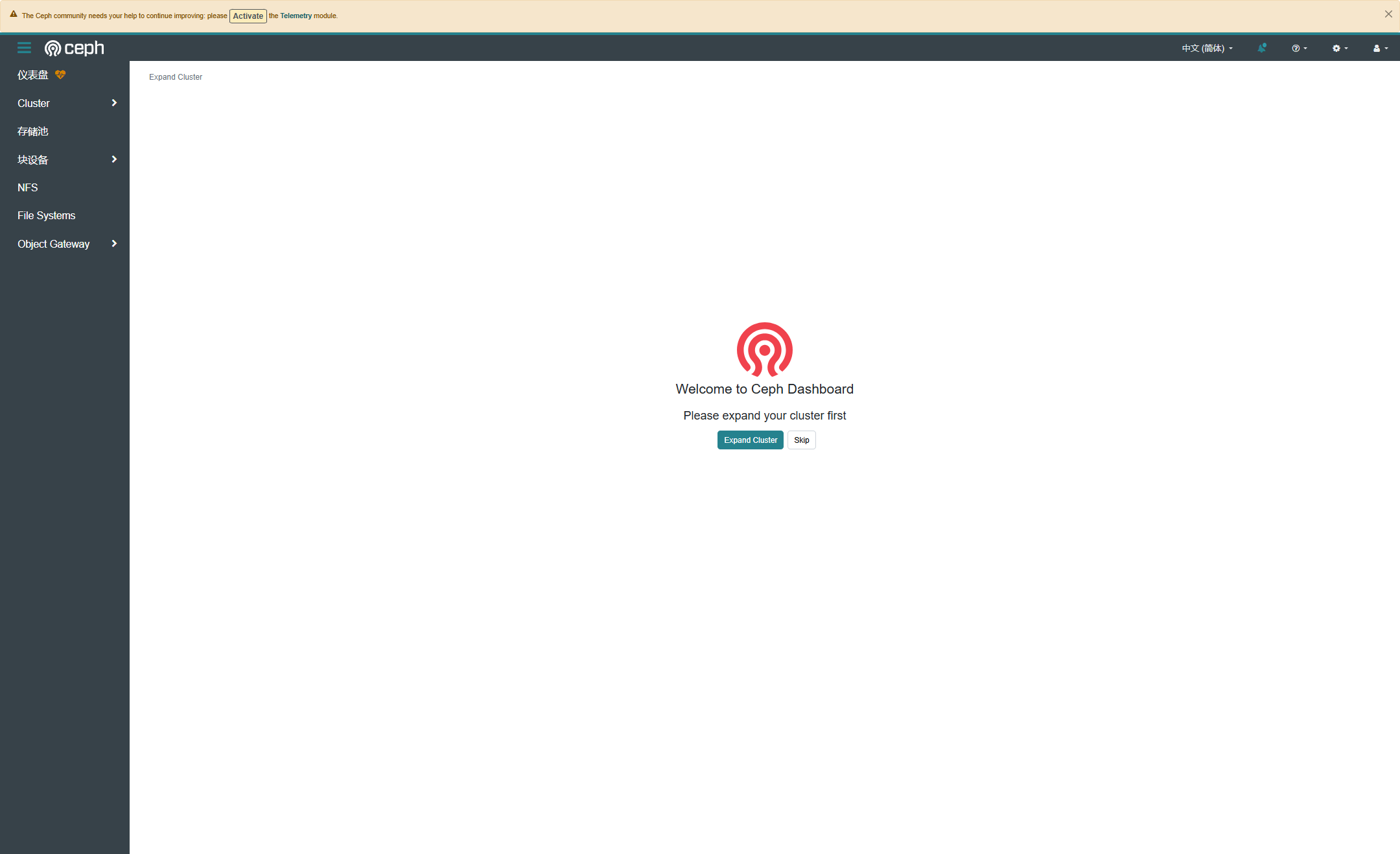
默认可能不是简体中文,在左上角可以设置语言。此时创建集群其实就已经完成了,下面就要通过ceph来横向拓展。
横向拓展
下面开始下发ceph的公钥,通过cat /etc/ceph/ceph.pub命令查看公钥
[root@node1 ~]# cat /etc/ceph/ceph.pub
ssh-rsa AAAAB3NzaC1yc2EAAAADAQABAAABgQCtS7LcLNvkKkHBQCyxWV+b8RhIXymufjRE2qiUGFBJtaJwYGy/zT+XFbBs49cQbzqsFfY3R8IiormDAnMmeWxeTs20mrYBhCquFUAXDD+pO3ZlAuptVWK+2FB1ip7Ptj/PcP5CR5ONASbGc/m3Fcbq/scDrCqZOkw/9QOU2VP2X0swtMp4vEnThDYbsiic3oRwwWtJm9H+EWxmBBfaPZ0lFFrjsTV951LmFgnkvLZh6e4mHwQ7pCWfNcjvN5Ze5Xgjz5w6Evgx8UZ2tA+TAmHQ9dxBoyiGHm4a1iUh6CZW7/F1RZ+jCfN1o6emNqUOUzQDSr4UruFlIJfE0K1N0Zuq8OUv0B/ErmjGplz6k1UbhE77On63Ia/aiM3YIiqAAZLHMxOYUiUbvUpIChk84fkx0iVTyGCwVQ9X22+FmdGL3rr5OkLnm6aHkIQTfNgNdXQkDj864hTARYS3hu5rVIMu2cv7TCXPmDwo4cp6My/JshmV9we9KFarucoWRrT3CEU= ceph-81ecd502-cf4e-11ef-baaf-000c297bc826把他复制到各个主机root用户的ssh信任公钥中,命令如下
cat >> ~/.ssh/authorized_keys <<EOF
# CEPH PUB
ssh-rsa AAAAB3NzaC1yc2EAAAADAQABAAABgQCtS7LcLNvkKkHBQCyxWV+b8RhIXymufjRE2qiUGFBJtaJwYGy/zT+XFbBs49cQbzqsFfY3R8IiormDAnMmeWxeTs20mrYBhCquFUAXDD+pO3ZlAuptVWK+2FB1ip7Ptj/PcP5CR5ONASbGc/m3Fcbq/scDrCqZOkw/9QOU2VP2X0swtMp4vEnThDYbsiic3oRwwWtJm9H+EWxmBBfaPZ0lFFrjsTV951LmFgnkvLZh6e4mHwQ7pCWfNcjvN5Ze5Xgjz5w6Evgx8UZ2tA+TAmHQ9dxBoyiGHm4a1iUh6CZW7/F1RZ+jCfN1o6emNqUOUzQDSr4UruFlIJfE0K1N0Zuq8OUv0B/ErmjGplz6k1UbhE77On63Ia/aiM3YIiqAAZLHMxOYUiUbvUpIChk84fkx0iVTyGCwVQ9X22+FmdGL3rr5OkLnm6aHkIQTfNgNdXQkDj864hTARYS3hu5rVIMu2cv7TCXPmDwo4cp6My/JshmV9we9KFarucoWRrT3CEU= ceph-81ecd502-cf4e-11ef-baaf-000c297bc826
EOF免密添加好之后可以通过仪表盘直接添加主机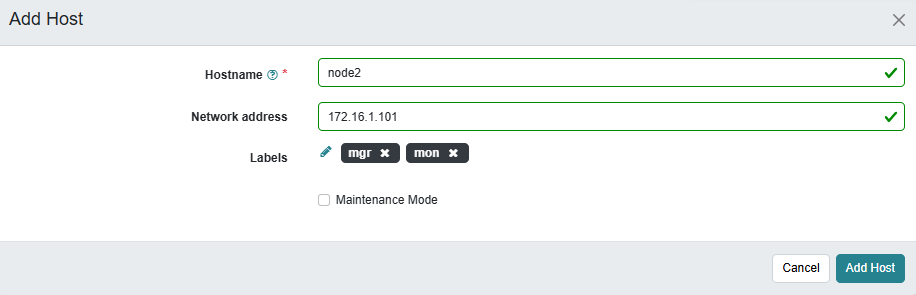
我这里通过命令的方式来添加,命令如下
#在Bootstrap节点上操作添加节点
ceph orch host add node2 --labels=mon,mgr
ceph orch host add node3 --labels=mon返回信息如下
[root@node1 ~]# ceph orch host add node2 --labels=mon,mgr
Added host 'node2' with addr '10.0.0.151'
[root@node1 ~]# ceph orch host add node3 --labels=mon
Added host 'node3' with addr '10.0.0.152'等待一会,面板中已经全部同步了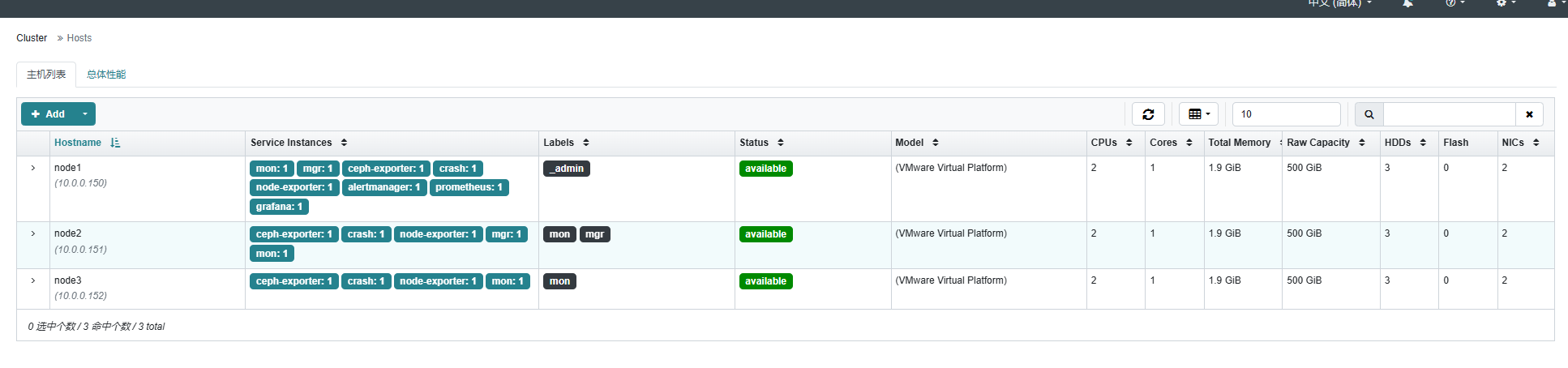
现在OSD还没有创建,只是把管理组件和监控组件装上了,下面开始创建OSD
OSD创建
在Ceph中,想要被管理的硬盘变成OSD必须是没有分区的,不然没法用,所以磁盘装上之后不需要管了就。在三台节点中,磁盘应该都是这种情况
[root@node2 ~]# lsblk
NAME MAJ:MIN RM SIZE RO TYPE MOUNTPOINTS
sda 8:0 0 300G 0 disk
├─sda1 8:1 0 2G 0 part /boot
└─sda2 8:2 0 298G 0 part
├─vg00-root 253:0 0 100G 0 lvm /
└─vg00-swap 253:1 0 4G 0 lvm [SWAP]
sdb 8:16 0 100G 0 disk
sdc 8:32 0 100G 0 disk
sr0 11:0 1 1.8G 0 rom 也可以在bootstrap节点,可以通过ceph orch device ls命令查看节点的硬盘情况
[root@node1 ~]# ceph orch device ls
HOST PATH TYPE DEVICE ID SIZE AVAILABLE REFRESHED REJECT REASONS
node1 /dev/sdb hdd 100G Yes 4m ago
node1 /dev/sdc hdd ATA_VMware_Virtual_SATA_Hard_Drive_00000000000000000001 100G Yes 4m ago
node1 /dev/sr0 hdd VMware_Virtual_IDE_CDROM_Drive_10000000000000000001 1808M No 4m ago Has a FileSystem, Insufficient space (<5GB)
node2 /dev/sdb hdd 100G Yes 22m ago
node2 /dev/sdc hdd ATA_VMware_Virtual_SATA_Hard_Drive_00000000000000000001 100G Yes 22m ago
node2 /dev/sr0 hdd VMware_Virtual_IDE_CDROM_Drive_10000000000000000001 1808M No 22m ago Has a FileSystem, Insufficient space (<5GB)
node3 /dev/sdb hdd 100G Yes 8m ago
node3 /dev/sdc hdd ATA_VMware_Virtual_SATA_Hard_Drive_00000000000000000001 100G Yes 8m ago
node3 /dev/sr0 hdd VMware_Virtual_IDE_CDROM_Drive_10000000000000000001 1808M No 8m ago Has a FileSystem, Insufficient space (<5GB) 在bootstrap节点,执行下面命令来添加管理的硬盘,现在把SDB和SDC都创建成OSD,执行下面命令
ceph orch daemon add osd node1:/dev/sdb
ceph orch daemon add osd node2:/dev/sdb
ceph orch daemon add osd node3:/dev/sdb
ceph orch daemon add osd node1:/dev/sdc
ceph orch daemon add osd node2:/dev/sdc
ceph orch daemon add osd node3:/dev/sdc添加好之后的仪表盘数据
集群状态
在bootstrap节点执行下面命令可以查看集群的相关状态
ceph -s
ceph health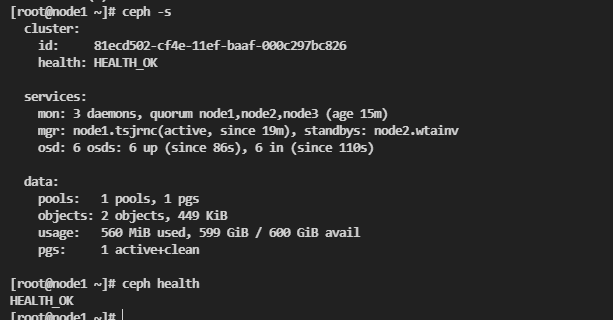
其他
bootstrap节点很重要,他是集群的创建者,在仪表中也会有一个_admin的标签,只有他才会生成/etc/ceph/ceph.client.admin.keyring文件,也是因为这个文件只有他才管理集群,其他的主机是无法管理集群的。
